
ShowUI: Дэлгэцийн зургаас бүх зүйлийг ойлгодог 2B параметрт модель
Бид өдөр бүр утас, компьютер дээрээ товчлуур дарж, цэс нээж, текст бичдэг. Энэ бүхнийг AI хийж чадвал яах вэ? ShowUI яг энэ зүйлийг хийнэ — дэлгэцийн зургийг нүдээрээ харж, юу хаана байгааг ойлгоод, хүний оронд товчлуур дарна. CVPR 2025-д хүлээн зөвшөөрөгдсөн энэхүү ажил Сингапурын NUS болон Microsoft-ын хамтарсан судалгаа юм.

Дэлгэцийн зургийг оруулж, ShowUI модель боловсруулаад, JSON үйлдэл гаргана: CLICK, TYPE гэх мэт.
Асуудал
Одоогийн GUI агентуудын бэрхшээл
Одоо байгаа ихэнх GUI автоматжуулалтын систем HTML код, accessibility tree зэрэг текст мэдээлэл дээр суурилдаг. GPT-4V шиг том загвар "энэ вебсайтын HTML-ийг уншаад товчлуур хаана байгааг хэл" гэж ажилладаг. Гэхдээ бодоод үз — хүн HTML код уншдаггүй шүү дээ. Бид дэлгэцийг нүдээрээ харж, товчлуур ямар өнгөтэй, хаана байгааг шууд мэдэрдэг.
Текстэд суурилсан арга хэд хэдэн сул талтай:
Хаалттай API-д хамааралтай
GPT-4V, Claude зэрэг хаалттай загварт хандах шаардлагатай. Үнэтэй, удаан, хязгаарлагдмал.
HTML бүтэц байж л таараа
Зарим апп accessibility tree-гүй, зарим вебсайт HTML бүтэц нь эмх замбараагүй. Текст мэдээлэл байхгүй бол юу ч хийж чадахгүй.
Хүний харах арга биш
Хүн дэлгэц рүү харахдаа HTML парс хийдэггүй. Визуал мэдээлэл — өнгө, байрлал, хэлбэр дүрсийг шууд ойлгодог.
Дэлгэцийн зургийн хэмжээ
Нэг screenshot 1344×756 нарийвчлалтай бол 5000+ токен үүсгэнэ. Энэ нь тооцоолол маш их шаарддаг.
Шийдэл
ShowUI: Визуал ойлголтоос үйлдэл хүртэл
ShowUI бол Vision-Language-Action (VLA) загвар. Нэрнээс нь харахад гурван зүйлийг нэгтгэсэн: дэлгэцийн зургийг харах (Vision), хэрэглэгчийн заавыг ойлгох (Language), бодит үйлдэл гаргах (Action). Qwen2-VL-2B суурь загвар дээр бүтээсэн бөгөөд зөвхөн 2 тэрбум параметртай — 18B параметртай CogAgent-аас 9 дахин жижиг.
Гэхдээ жижиг гэдэг нь сул гэсэн үг биш. ShowUI гурван гол шинэлэг зүйл нэвтрүүлсэн:
UI-Guided Visual Token Selection
Дэлгэцийн зургийн давхардсан хэсгийг автоматаар олж, шаардлагагүй токенуудыг хасна.
Interleaved VLA Streaming
Визуал мэдээлэл, текст, үйлдлийг нэг урсгалд холин боловсруулна.
Чанартай өгөгдлийн жор
256K жижиг боловч сайтар сонгосон сургалтын өгөгдөл ашиглана.
Шинэлэг #1
UI-Guided Visual Token Selection
Энэ бол ShowUI-ийн хамгийн сонирхолтой санаа. Асуудал нь энгийн: дэлгэцийн зураг дээр ихэнх хэсэг нь цагаан дэвсгэр, хоосон зай, давтагдсан хэв маяг. Google хайлтын хуудсыг бод — дэлгэцийн 70% нь цагаан хоосон зай. Тэгвэл яагаад эдгээр бүх пикселийг дүн шинжилгээ хийх хэрэгтэй гэж?
ShowUI-ийн арга:
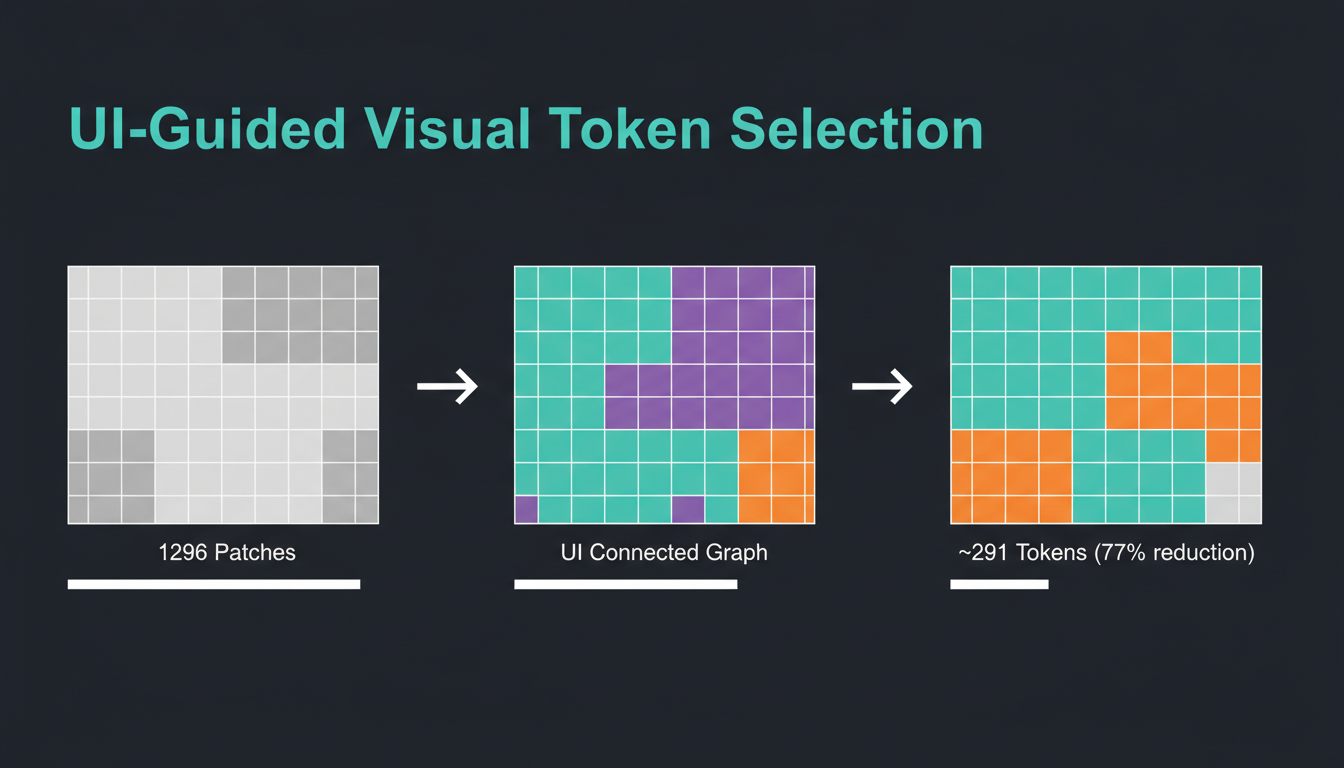
1296 patch → UI Connected Graph → ~291 токен (77% буурал). Давхардсан хэсгийг хасаж, чухал элементүүдийг хадгалсан.
Яагаад Token Merging биш Token Selection вэ гэвэл — token merging хийхэд positional information алдагдана. Товчлуур яг хаана байгааг мэдэхийн тулд байрлалын мэдээлэл заавал хэрэгтэй. ShowUI-ийн арга бол сонгогдсон токенуудын original position embedding-ийг хадгалдаг. Тиймээс self-attention анхны байрлалын харилцааг бүрэн ойлгоно.
Бас нэг давуу тал: энэ арга нэмэлт сурах параметр нэмдэггүй. Сургалтын үед санамсаргүй сонголт хийж, inference-ийн үед сонголттой ч, сонголтгүй ч ажиллах боломжтой.
Шинэлэг #2
Interleaved Vision-Language-Action Streaming
GUI navigation бол нэг удаагийн үйлдэл биш. "Las Vegas руу нислэгийн тасалбар хай" гэсэн даалгавар бол хэд хэдэн алхам: хайлтын хэсэгт бичих → хайх товч дарах → үр дүнгээс сонгох → огноо оруулах. Алхам бүрийн дараа дэлгэц өөрчлөгдөнө, модель шинэ дэлгэцийг ойлгож, дараагийн үйлдлийг шийдэх ёстой.
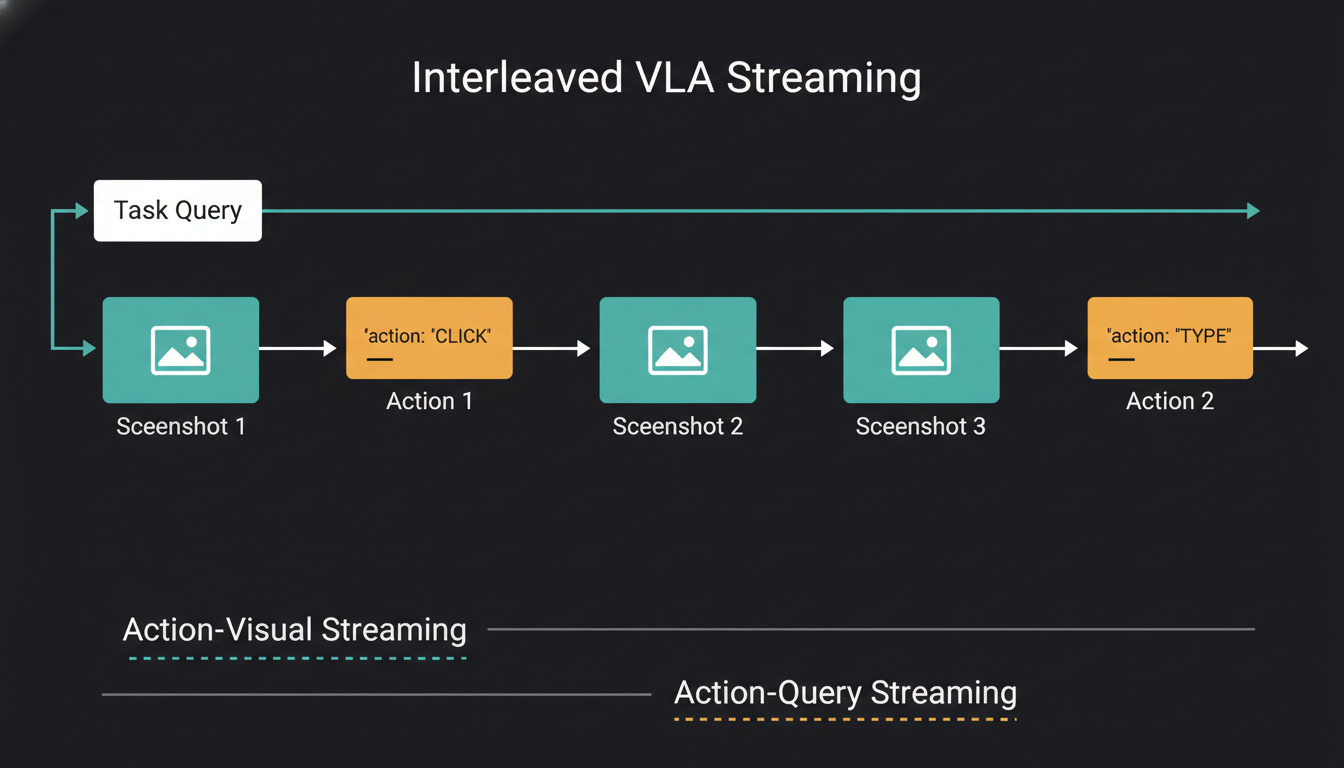
Screenshot → Action → Screenshot → Action гэсэн interleaved урсгал. Визуал болон текст мэдээллийг хослуулан боловсруулна.
ShowUI хоёр горимоор ажилладаг:
Action-Visual Streaming
Дэлгэцийн зураг + өмнөх үйлдлийн түүх хамтдаа дамжина. Гар утасны навигацид онцгой чухал — апп солигдоход дэлгэц бүрэн өөрчлөгдөнө.
Action-Query Streaming
Нэг дэлгэцийн зураг дээр олон query, олон үйлдэл хослуулна. Grounding даалгаварт илүү тохиромжтой — нэг зурган дээр олон элемент олох.
Бүх үйлдлийг JSON форматаар стандартчилсан нь онцлог. {"action": "CLICK", "value": "element", "position": [x, y]} гэсэн нэгдсэн формат вэб, гар утас, десктоп гурвуулан дээр ажиллана. Координатууд 0-1 хооронд харьцангуй утгаар илэрхийлэгддэг болохоор дэлгэцийн хэмжээнээс хамааралгүй.
Мөн action space-ийг тайлбарласан README баримт бичгийг системийн промпт болгон өгдөг. Модель action-ийг цээжлэхийн оронд README-г уншиж, функц дуудлага хийдэг байдлаар ажиллана. Шинэ action төрөл нэмэхэд модель дахин сурах шаардлагагүй.
Шинэлэг #3
Сургалтын өгөгдлийн жор
Их өгөгдөл = сайн модель гэсэн ойлголт үргэлж үнэн биш. SeeClick 1.06M screenshot ашигласан бол ShowUI зөвхөн 256K ашигласан — гэхдээ үр дүн нь илүү сайн. Яагаад?
Судлаачид өгөгдлийн төрөл бүрийг нарийн шинжилсэн:
Өгөгдлийн чанарын шинжилгээ
Вэб өгөгдөл дэх текст элементүүд ("static text") нийт 40%-ийг эзэлдэг. Гэвч ихэнх VLM-ууд OCR-ийн чадвартай аль хэдийн тул static text-ээс сурах зүйл бага. Тиймээс ShowUI зөвхөн визуал элементүүд — товчлуур, checkbox, dropdown зэргийг хадгалж, static text-ийг хассан. 270K screenshot-аас 22K болтлоо шүүсэн ч гүйцэтгэл буураагүй, харин ч сайжирсан.

Вэб 22K, Гар утас 97K, Десктоп 100 зурагтай. Нийт 256K instance, 2.7M annotation. Balanced sampling стратеги ашигласан.
Desktop өгөгдөл онцгой бэрхшээлтэй. OmniAct датасет зөвхөн 100 зурагтай, 2K элементтэй. Элемент бүр зүгээр л "message_ash" гэх мэт нэртэй — ямар ч тайлбаргүй. ShowUI баг GPT-4o-г ашиглан элемент бүрийг гурван талаас тайлбарлуулсан: харагдах байдал, орон зайн байрлал, хэрэглэгчийн зорилго. 2K элементээс 8K болгон өсгөсөн.
Хамгийн чухал нь — тэнцвэржүүлсэн sampling. Вэб 22K, гар утас 97K, десктоп 100 гэсэн огцом тэнцвэргүй өгөгдлийг batch бүрт төрөл бүрийг тэнцүү магадлалтайгаар оруулах стратеги ашигласан. Энэ нь 3.7% нарийвчлалын ахиц авчирсан.
Үр дүн
Жижиг загвар, том үр дүн
Тоонууд өөрсдөө ярьж байна:
Screenspot benchmark дээрх zero-shot grounding үр дүн — ShowUI ямар ч fine-tuning-гүйгээр дэлгэцийн элементийг олох чадвар:

CogAgent (18B) 47.4%, SeeClick (9.6B) 53.4%, ShowUI (2B) 75.1%. Хамгийн жижиг загвар, хамгийн өндөр нарийвчлал.
CogAgent
SeeClick
ShowUI
9 дахин том загвараас 28 нүүлийн пунктээр илүү гарсан. Бага өгөгдөлтэй, бага параметртай. Энэ бол зүгээр л шоу биш, бодит ахиц.
Навигацийн даалгаварт ч мөн адил сонирхолтой. Mind2Web вэб навигацид ShowUI-ийн zero-shot гүйцэтгэл SeeClick-ийн pretrained + fine-tuned гүйцэтгэлтэй дүйцсэн. AITW гар утасны навигацид interleaved streaming нь VLM baseline-аас 1.7% нэмэлт ахиц авчирсан — visual context гар утасны олон апп-тай орчинд маш чухал.
MiniWob онлайн орчинд ShowUI-ийн zero-shot үр дүн 27.1% байсан бол fine-tuned Qwen-VL 48.4% байсан. Энэ зөрүү нь онлайн орчинд offline сургалт хангалтгүй гэдгийг харуулж байгаа — reinforcement learning-тэй хослуулах шаардлагатай.
Ablation
Юу ажилладаг, юу ажилладаггүй вэ?
Судлаачид нэг нэгээр нь салгаж туршсан:
- Token Selection vs Token Merging: Token merging 1.6× хурдасгал өгсөн ч screenshot нарийвчлал 42.3% болж унасан. Token selection 1.5× хурдасгалтайгаар 70.8% нарийвчлал хадгалсан. Positional information алдагдахгүй байх нь grounding-д маш чухал.
- Selection ratio 0.5 хамгийн тохиромжтой: Хагас токенийг хасах нь хурд ба чанарын хоорондох шилдэг тэнцвэр. 0.75 бол 68.3%, 1.0 бол бүрэн sequence 64.5%.
- Cross-layer insertion: Token selection-ийг аль давхаргад оруулах вэ гэдэг чухал. Cross-layer (ээлжлэн оруулах) нь бүх давхаргад оруулахаас, эсвэл зөвхөн эхэнд/төгсгөлд оруулахаас илүү сайн ажилласан.
- Balanced sampling 3.7% ахиц: Тэнцвэржүүлсэн sampling-гүйгээр модель вэб өгөгдөлд хэт тохирч, десктоп дээр муу ажилладаг.
- Visual context чухал: ShowUI-ийн interleaved streaming-гүй хувилбар (зөвхөн action) baseline-аас ердөө 1.1% дээгүүр. Visual history нэмэхэд нэмэлт 1.7% ахиц — нийт 2.8%.
Хязгаарлалт
Юуг хийж чадахгүй вэ?
Шударгаар хэлэхэд ShowUI-д мэдэгдэхүйц хязгаарлалт бий:
Нэгд, загвар бүхэлдээ offline өгөгдөл дээр сурсан. Бодит орчинд гэнэтийн popup гарч ирэх, хуудас удаан ачаалагдах, алдааны мэдэгдэл гарах зэрэг тохиолдлуудыг сурах боломжгүй. MiniWob-ийн үр дүн (27.1% zero-shot) үүнийг тодорхой харуулж байна.
Хоёрт, cross-domain generalization бэрхшээлтэй. Mind2Web дээр cross-website тохиргоо нь same-website-аас мэдэгдэхүйц муу. Модель тухайн вебсайтын загварыг сурсан ч шинэ вебсайт дээр бүрэн шилжихэд хүндрэлтэй.
Гуравт, desktop өгөгдөл маш хязгаарлагдмал — зөвхөн 100 зураг. Windows, macOS, Linux бүгдийг хамарсан ч гэсэн энэ нь хангалттай биш. Desktop дээрх гүйцэтгэл бусад платформоос доогуур байгаа нь үүнтэй шууд холбоотой.
ShowUI нь GUI агентын чиглэлд маш чухал алхам. Хүний нүдний хараагаар дуурайлган, дэлгэцийн зургийг шууд ойлгож, үйлдэл хийх чадвар — 2 тэрбум параметрт модельд.
Гол сургамж? Зөв арга, зөв өгөгдөл байвал жижиг модель ч том загвараас давж чадна. UI Connected Graph-аар токен хасах, interleaved streaming-аар олон алхамт навигаци хийх, balanced sampling-аар цөөн өгөгдлөөс максимум ашиг гаргах — энэ гурав хослоход 2B модель 18B-аас давна.
Ирээдүйд reinforcement learning нэмж, бодит онлайн орчинд сургах нь дараагийн том алхам байх болно. ShowUI-ийн код, модель бүгд нээлттэй: github.com/showlab/ShowUI
Эх сурвалж: Lin et al., "ShowUI: One Vision-Language-Action Model for GUI Visual Agent", CVPR 2025. Show Lab @ NUS + Microsoft.


